Extracting dates from unstructured text
In this post I discuss an idea on how we can extract dates from unstructured text. The main issue is that dates a written in all sorts of formats and I want to extract and normalize all of them. My previous approach consisted of generating regular expressions, mapping each pattern to a date format. However, this quickly proved to be way too slow. Though I could’ve tuned the performance by combining the patterns or use things like pyparsing, I decided to look for other alternatives. In summary I use Aho-Corasick to find parts of dates and generate another trie to detect valid dates. The technique has enabled me to extract dates in time linear to the size of the text plus the number of results. This means that the time required to search is pretty much the same regardless if we search for a single format or a hundred. My primary application for the technique is to generate semantic timelines from unstructured text.
Say the have some text we want to extract dates from:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Pellentesque pretium lacus sem, in vehicula sem pulvinar eget. Ut elementum 2014.03.15 commodo massa, eu varius eros ultricies quis. Integer nisi mauris, tempor vitae laoreet gravida, vulputate ac magna. Nulla finibus faucibus elementum. Aliquam 2012/11/13 placerat accumsan est in imperdiet. Nam lorem ligula, pretium porttitor nulla sed, ultricies faucibus nunc. In pulvinar purus ut semper 08.08.08 pharetra. Nullam purus nibh, malesuada eget erat sed, viverra viverra ligula.
As you see, there are three dates within the text (The last one illustrates how inherently impossible it is to get this thing completely right). To the extent I’ve found work similar to this one, regular expressions have been the suggested solution. The expressions need to be mapped to their corresponding date formats to determine the actual date. However, regular expressions are either slow, ugly, or both, and we don’t really need them here at all.
But for now: If we take a closer look at the dates, we see that there’s actually just two different types of patterns we are matching: 2 digits and 4 digits. So instead of using a regular expression like this:
(\d{2,4}(?:(.|)\d{2}(?:(.|)\d{2}) # -> ["2014.03.15", "2012/11/13", "08.08.08"]we could’ve used this:
(\d{4}|\d{2}) # -> ["2014", "03", "15", "2012", "11", "13", "08", "08", "08"]With the new stream of individual components, we don’t really have a way of knowing where a valid date starts and where it ends. For that we need a multi-pattern matching algorithm. Enter Aho-Corasick.
Aho-Corasick is a finite state machine capable of matching large amounts (tens of thousands) of pattern within a text in time linear to the length of the text plus the number of matches. Given our text above and search terms ["consectetur", "ultricies"], it will yield three results.
The Aho-Corasick algorithm looks for exact patterns within a string, so we will have to add every possible part of a date to the dictionary. But hey, even with a large number of locale names and timezone, we will probably not go into the order of tens of thousands of patterns.
Yo dawg, I heard you like tries, so I’m gonna to put a trie on that trie
Aho-Corasick uses a datastructure called a trie. This trie represents a set of nodes (“states”) and relationships between them. Each state has a suffix string, representing a valid prefix of one or more of our patterns (“pre” is a prefix to pattern “preben”). When a new piece of data arrives, one of six things may happen:
- The current prefix + the new data is a prefix of one or more of our patterns
- Same as above but the prefix and new data is one of our patterns
- The current prefix + the new data is not valid, but we have a shorter prefix that is
- Same as above, but the shorter prefix and the new data is one of our patterns
- There is no valid new prefix with the new data, but the new data is a valid prefix
- Same as above, but the new data is not a valid prefix
Each node in the trie maintains a record of the longest prefix that will be valid if itself fails. If we for example have the patterns prebenand bejamin, the state prebe will point to the state be. This way, if we are in state prebe and new data j arrives (eliminating preben as a match), we can jump directly from prebe to bej. If something else arrived, we would have to check if the state be were pointing to any shorter suffixes.
By adding all possible values that may into a date (years, dates, months, month names, weekdays and timezones), we are able to efficiently identify the next longest possible component of a date. Each of these components are labeled with the type of value they represent (full_year, short_year, month, date, ...). As you proably notice, there certain values that collide, like dates, months, hours, minutes and seconds which all have valid values from 01-12. I’ve handled this by labelling those parts things like one_two_digits.
Based on these labels I create my own trie. Each state represent a label added to the current prefix. Below is an example of three “patterns”:
1: [date].[month].[full_year]
2: [full_year].[month].[date] [hour]
3: [month].[date].[full_year]From these patterns I generate a trie that consist of states and relationships looking like this:
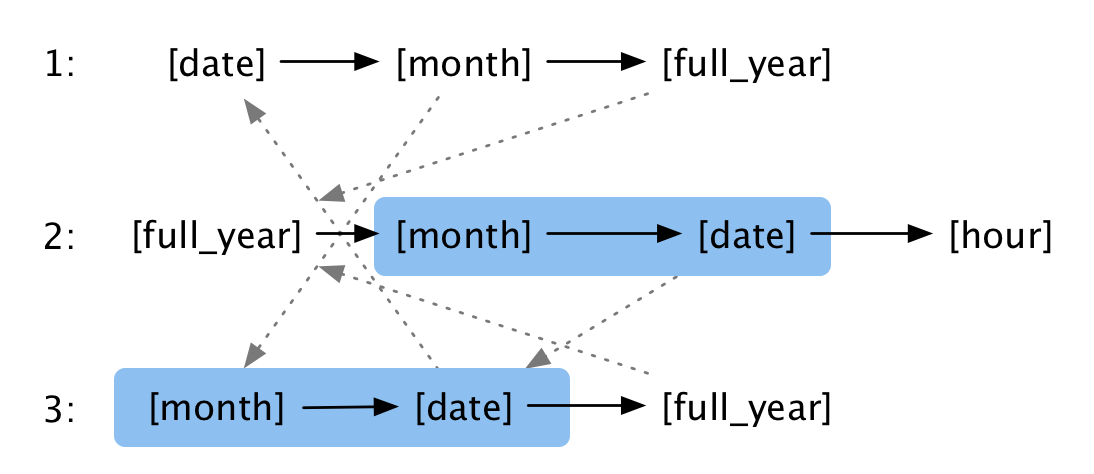
The black arcs show valid next values from a given state, the blue lines show the longest alternative prefix. The blue boxes are to illustrate how we can jump from one prefix to another. At data 2012.06.13, format 2 is the best candidate. However, it requires an hour to be present and when a full year arrives instead, format 3 is a valid format. Because the states here are labels, not actual values, we need to maintain a buffer that holds the actual string being matched.
Each pattern is mapped to one or more date formats so that we can convert the string into e.g. unix timestamps. In cases where a string matches several formats (e.g. 2013.03.06), the result from both normalizations is kept.
The algorithm checks that the new data is within a single character from the of the previous data, to enable separators like “.” and “/”. It also allows these separators to be part of the date formats, this helps reduce the number cases where string must be parsed with multiple formats.
So there you have it. By using Aho-Corasick to identify parts of what may be a date within a text, combined with my own trie to see if those parts together make up a valid date, I’m able to extract a wide range of different date formats almost as efficiently as I would extract a single date format. One issue with doing this is overlapping values, for example that the algorithm think it sees a full year (2010), but actually is a month and a date (20th of October).