Context-independent named entity recognition

Statistical approaches to Named Entity Recognition are trained for specific types of text and sometimes deliver poor performance on others, either due to language or formatting. Purely empirical approaches, like the one presented here, do not have this limitation and may thus be better suited for the messy data of digital investigations, as well as being easier to explain. Code and experimental corpus is made available. Feel free to send me an email if you would like to get the model.
Introduction
Named Entity Recognition (NER) is the process of extracting rigid designators from unstructured text. These entities are typically organized in classes like people, organizations and locations.
NER may be valuable during digital investigations for a number of reasons. First, generating a histogram of names in a datasets provides a quick overview that may help guide further analysis. By combining names with other types of entities, like phone numbers and e-mail addresses, we may also generate a network of entities belonging to the same person and thus create a more complete social network from our data.
However, Conditional Random Field (CRF) an other statistical methods for NER can be quite annoying. They don’t always recognize all instances of the exact same name when it’s in different contexts (different content before and after). An example from the Enron dataset using Stanford CRF NER with the english.all.3 classifier: The text Christopher S Smart yields a true positive, while kema@pplmt.com; Christopher S Smart; dacluff@duke.com; does not. Assistant to Louise Kitchen yields a true positive, while cc: Mel Dozier/ECT, Louise Kitchen/LON@ECT Subject: yields Mel Dozier/ECT”, Louise, messing up both names.
Historically, approaches to Named Entity Recognition have been based on either statistical models or expert rules, both usually supported by some empirical data. In this post I present an almost entirely empirical approach on the rationale that the best way to find all names is to know every name. This is probably impossible, but mining the Internet for names makes it possible to get close enough to make it interesting. I call the method Namefinder.
Some benefits of a context independent and empirical approach during a digital investigation, are that all instances of the same name are guaranteed to be recognized, and that the results (IMO) are easier to explain (either the name is in the model or it’s not).
In contrast to other approaches, this one is limited to people only. Furthermore, valid names must consist of at least two words.
Experiments are performed against three manually labelled datasets and compared against Stanford CRF NER with classifier english.all.3. The 500newsgoldstandard [1] dataset is already labelled, but it’s missing a whole bunch of labels (e.g. “Justin Thomas” in record id=14) and has been adjusted. The other two are excerpts from the Enron corpus, and headlines retrieved from the Norwegian broadcaster NRK. The dataset is available here.
[1] https://github.com/AKSW/n3-collection (Copyright AKSW) (last accessed: 2016-09-03)
Model generation
This method relies completely on the supplied model. In cases where I already know the relevant names, those may be sufficient as a model. But most often this is not the case, and then I need a really big list. I’m not going to say where, but the list used here is from more than one open source on the Internet. It consists of more than 100 million unique names and 10 million unique words (tokens).
10 million tokens are impractical for three reasons; it’s big (over 220MB file), it consequentially takes longer to load the model, and it produces a lot of false positives. The model must therefore be pruned.
The goal of pruning is to minimize the number of tokens, maximize the true positive rate and minimize false positive rate. This is done in three steps, called mixed_case, infrequent and blacklist:
| Step | Goal | # Tokens | Model size | Avg. recall * | Avg. precision * |
|---|---|---|---|---|---|
| 0. original | Max. recall | 10046502 | 222MB | 0.94 | 0.47 |
| 1. mixed_case | Max. precision | 10008311 | 221MB | 0.91 | 0.65 |
| 2. infrequent | Min. size | 1125447 | 22MB | 0.88 | 0.65 |
| 3. blacklist | Max. precision | 1125438 | 22MB | 0.88 | 0.67 |
* Across the three evaluated datasets.
-
The mixed case pruning was done by finding and counting all lower cased words in the CoNLL 2002 corpus [2]. A token is pruned if its relative log frequency is significantly higher as lowercased than in the model.
-
All infrequent token, here those with relative log frequency lower than 0.07 was then pruned.
-
Finally, nine manually blacklisted tokens (
hallo hey hi ms mr sen gov dr hei) was pruned.
The result is a 22MB large model with just above 1 million unique tokens.
[2] http://www.cnts.ua.ac.be/conll2002/ner/ (Last accessed: 2016-09-03)
Name recognition
The approach is to compute the probability that two or more closely position, capitalized words is a name. It is done by first computing a probability score for each token x, as show here:
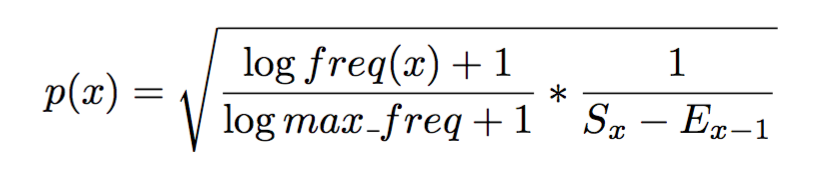
Sx is the start of the current token and Ex-1 is the end of the previous token. The probability score is thus also based on the distance between the two tokens. This allows for some content between the tokens, like abbreviations. The substring between two tokens, called gap, is also used to detect invalid strings, eliminating any potential results.
To allow for some blind tokens, a luck attribute is used, so that if a token is not in the dataset, it still has a chance of being included. The rationale is that it should be included if it many times occur together with valid tokens.
The probability for a set of tokens is simply their average probability.
The code for doing name recognition with namefinder.py given a model is well under 100 lines of code:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import math
import regex
import sys
import json
import random
__author__ = 'Petter Chr. Bjelland (post@pcbje.com)'
class Namefinder(object):
def __init__(self, reference_model, threshold=0.25, luck=0.1):
self.stop = regex.compile(ur'(%s)' % '|'.join([
'and', 'or', 'og', 'eller', '\?', '&', '<', '>', '@', ':', ';', '/',
'\(','\)', 'i', 'of', 'from', 'to', '\n', '!']), regex.I | regex.MULTILINE)
self.semistop = regex.compile(ur'(%s)' % '|'.join([',']), regex.I | regex.MULTILINE)
self.tokenizer = regex.compile(ur'\w{2,20}')
self.suffixes = set(['s', 'h'])
self.luck = luck
self.threshold = threshold
with open(reference_model) as file_object:
self.model = json.load(file_object)
def extract(self, text):
token_buffer = [('', (-1, -1))] * 4
for index, token in enumerate(self.tokenizer.finditer(text)):
relative_index = index % len(token_buffer)
token_buffer[relative_index] = (token.group(), (token.start(), token.end()))
probability = 0
prev_token_start = -1
for token_distance in range(len(token_buffer)):
buffer_index = (relative_index - token_distance) % len(token_buffer)
buffered_token, (token_start, token_end) = token_buffer[buffer_index]
is_lowercase = buffered_token == buffered_token.lower()
token_probability = self.model.get(buffered_token.lower(), 0)
valid_suffix = any([buffered_token.endswith(suffix) for suffix in self.suffixes])
if not token_probability and valid_suffix:
buffered_token = buffered_token[0:-1]
token_probability = self.model.get(buffered_token.lower(), 0)
if not token_probability and random.random() <= self.luck:
token_probability = 0.5
if is_lowercase or not token_probability:
break
if token_distance > 0:
gap = text[token_end:prev_token_start]
if self.stop.search(gap):
break
token_probability *= math.sqrt(float(1) / len(gap))
prev_token_start = token_start
probability += token_probability
score = (probability / (token_distance + 1))
if score >= self.threshold and 1 <= token_distance <= 4:
yield token_start, token.end(), text[token_start:token.end()]
if token_distance > 0 and self.semistop.search(gap):
break
if __name__ == '__main__':
_, reference_model, input_path = sys.argv
with open(input_path) as file_object:
text = file_object.read()
for name in Namefinder(reference_model).extract(text):
print nameExperimental setup
The experiments are performed on three labelled datasets, nrk, enron, and news500. Note that the nrk dataset is in Norwegian so classifiers trained for english text are expected to under perform. Still, in investigations we may not in advance which languages we are dealing with, so it is not an unrealistic scenario. Some statistics on the datasets:
| Dataset | # Records | # Unique names |
|---|---|---|
| nrk | 245 | 320 |
| 500news | 245 | 329 |
| enron | 63 | 408 |
For these experiments, namefinder is compared against Stanford CRF NER (2015-12-09) [3] with classifier english.all.3class.distsim.crf.ser.gz. This classifier detect single word names, however these are excluded before computing results to produce comparable results.
Namefinder runs with parameters threshold 0.2 and luck 0.1.
Results are computed based on values true_positive, false_positive and actual_positive. All three values hold distinct names, so it does not affect the results how many times a potential name is recognized. Based on these values, the statistical measures recall (ratio of actual names found), precision (ratio between true and false positives) and F1 score (their harmonic average) is computed.
[3] http://nlp.stanford.edu/software/CRF-NER.shtml (Last accessed: 2016-09-03)
Results
NRK (Norwegian)
| Method | Recall | Precision | F1 |
|---|---|---|---|
| stanford crf ner | 0.64 | 0.66 | 0.65 |
| namefinder | 0.84 | 0.57 | 0.68 |
500NEWS
| Method | Recall | Precision | F1 |
|---|---|---|---|
| stanford crf ner | 0.91 | 0.94 | 0.93 |
| namefinder | 0.92 | 0.74 | 0.82 |
ENRON
| Method | Recall | Precision | F1 |
|---|---|---|---|
| stanford crf ner | 0.38 | 0.60 | 0.47 |
| namefinder | 0.89 | 0.67 | 0.76 |
Discussion
The results above show that namefinder maintains a more stable high recall, at the cost of lower precision. I argue that the false positives are still manageable. The tradeoff between recall and precision depends on the selected parameters threshold and luck.
One of the reasons Stanford NER performs so poorly on the enron data is that many names are on a format where the family name comes first, like Bjelland, Petter, which it does not recognize. It can surely be trained to also accept such formats, but it underlines the point about unpredictability.
There are several reasons why namefinder has a pretty low precision. One of them is that it generates every subset of a name, so Petter Chr. Bjelland produces Petter Chr., Chr. Bjelland and Petter Chr. Bjelland. Two of those will likely be false positives.
Namefinder is (IMO) pretty fast. It takes 1.2 seconds to load the model, and it searches Peter Norvigs big.txt [4], which is 6.2MB of text in 3.2 seconds. On that file it means almost 300K words per second.
The whole model must fit in memory, and currently the whole text is as well. During the search phase the memory use is constant as a ring buffer is used to store the last N tokens.
It may seem weird that the CoNLL 2002 dataset is not part of the experiments. As the challenge includes single word tokens, it seems to me like a fair comparison is not possible. Either I would have to remove the singles from that dataset (which could skew the results in my favor), or I would have to count them all as false negatives (which doesn’t sound fair either).
Finally, as statistical and empirical approaches may complement each other, it’s a good idea to combine the two during investigations.
[4] http://norvig.com/big.txt (Last accessed: 2016-09-03)